
티스토리 뷰
부하 분산을 위한 MySQL Replication 구성 및 쿼리 요청 분기
Overview
내가 진행하고 있는 SNS 프로젝트를 보면 Service Layer에 속해있는 거의 모든 메소드가 데이터베이스에 쿼리 요청을 보낸다. 나의 프로젝트 뿐 아니라 대부분 웹 서비스 프로젝트를 보면 사용자 데이터를 처리하기 위해 혹은 이를 기반으로 다양한 서비스를 제공하기 위해 데이터베이스에 무수히 많은 요청을 보낸다. 현재 사용하고 있는 MySQL 서버가 고사양이더라도 서버 한 대가 웹 서버로부터 오는 모든 트래픽을 견뎌내기에는 분명히 한계점이 드러나기 마련이다. 그로 인해 데이터베이스에 장애가 발생한다면 운영 중인 서비스에 바로 큰 타격을 줄 것이다. 따라서, Replication을 사용하여 MySQL의 환경을 구축해보려 한다.
왜 MySQL Replication 구성을 하는걸까?
아래 그림은 서비스용으로 가장 자주 사용되는 Replication 형태인 1:M 복제다. 1:M 복제는 하나의 마스터 MySQL 서버에 2개 이상의 슬레이브 MySQL 서버를 연결시키는 형태이다. 일반적으로 마스터 서버는 INSERT , UPDATE , DELETE 의 변경 작업을 슬레이브 서버는 SELECT 의 읽기 작업을 담당한다. 다음 그림을 참고하면서 Replication 구성에 대한 장점을 자세히 알아보자.
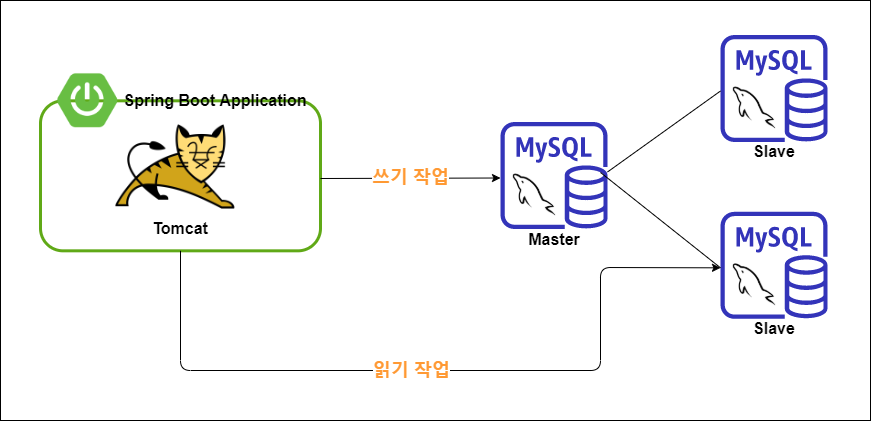
MySQL을 Replication을 통해 서버 환경을 구축하면 크게 두 가지 장점을 얻을 수 있다.
- 부하를 분산시킬 수 있다.
- 가용성이 높아진다.
보통 MySQL에서는 인덱스로 B-Tree 인덱스를 사용한다. 인덱스가 B-Tree 에 저장될 때는 저장될 키값을 이용해 B-Tree 상의 적절한 위치를 검색하고, 저장될 위치가 결정되면 B-Tree 의 리프 노드에 저장한다. 만약 리프 노드가 꽉 차서 더는 저장할 수 없을 때는 리프 노드가 분리돼야 하는데, 이는 상위 브랜치 노드까지 처리 범위가 넓어진다. 따라서, 키를 추가하는 작업은 디스크로부터 인덱스 페이지를 읽고 쓰기를 해야 하기 때문에 INSERT 나 UPDATE 문장을 처리하는데 상대적으로 시간이 더 오래 걸린다.
웹 서비스에서는 쓰기 작업보다 읽기 작업의 비중이 높기 때문에 모든 작업을 하나의 서버에서 모두 처리하기에는 위에서 설명한 쓰기 작업의 병목이 발생하면 다른 작업들의 처리까지 늦어지게 될 수 있다. 따라서, 서버를 확장하고 최대한 읽기 작업을 슬레이브 서버에서 처리하게끔 유도한다면 높은 부하를 견딜 수 있는 구조가 될 것이다.
만약 MySQL 서버가 한 대인 상황에서 장애가 발생한다면 관련된 모든 서비스들이 멈춰버리는 심각한 상황이 발생할 것이다. 하지만 Replication을 구성한다면 이런 상황에서 슬레이브 서버를 마스터로 승격시켜서 간단히 서비스를 복구하는 것이 가능하다. 물론 슬레이브 서버를 마스터로 승격시키기 위해 몇 가지 작업이 필요하지만 어느 정도 준비만 되어 있다면 짧은 시간 안에 충분히 처리할 수 있다.
Refactoring : 트랜잭션 단위로 쿼리 요청을 적절한 서버로 분기하기
Spring에서는 여러 개의 DataSource 를 하나로 묶고 자동으로 분기해주는 AbstractRoutingDataSource 클래스를 제공해준다. 만약 트랜잭션 단위가 아닌 쿼리 단위로 분기한다면 하나의 메소드 안에 쓰기 작업과 읽기 작업이 동시에 있는 경우, 마스터 서버에서 커밋된 데이터라 하더라도 커밋된 시점에 슬레이브에는 반영되지 않았을 수도 있다. 이렇게 되면 '데이터가 없다'는 응답을 받게 되므로 트랜잭션 단위로 분기하게 되었다. 또한, 현재 트랜잭션의 속성에 따라 사용할 DataSource 를 결정할 것이기 때문에 TransactionSynchronizationManager 와 함께 사용할 것이다. 다음은 AbstractRoutingDataSource 로직을 표현한 그림이다.
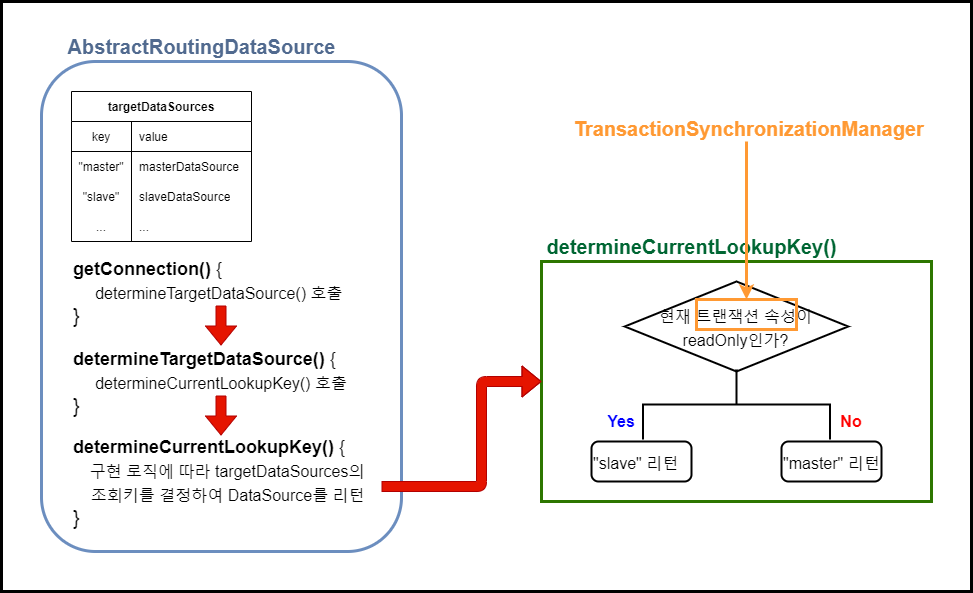
각 서버에 대한 DataSource 빈 등록하기
새로운 슬레이브 서버는 이미 준비 되어있다는 가정 하에 글을 작성하겠다. 먼저 DataSourceConfig 에서 새로 추가한 서버에 대한 DataSource 빈을 등록해야 한다. 그렇게 되면 DataSource 타입의 빈이 여러 개가 되므로 구분할 수 있도록 빈에 이름을 붙여준다.
@Configuration
@EnableTransactionManagement // 애너테이션 기반 트랜잭션 기능 활성화
@PropertySource("classpath:/db-secret.properties")
public class DataSourceConfig {
@Bean(name = "masterDataSource")
// 지정된 prefix로 시작된 속성값만 사용하겠다.
@ConfigurationProperties(prefix = "spring.datasource.master")
public DataSource masterDataSource() {
return DataSourceBuilder.create().build();
}
@Bean(name = "slaveDataSource")
@ConfigurationProperties(prefix = "spring.datasource.slave")
public DataSource slaveDataSource() {
return DataSourceBuilder.create().build();
}
@Bean
public PlatformTransactionManager transactionManager(@Qualifier(value = "proxyDataSource") DataSource dataSource) {
DataSourceTransactionManager transactionManager = new DataSourceTransactionManager();
transactionManager.setDataSource(dataSource);
return transactionManager;
}
}AbstractRoutingDataSource 객체 빈 등록하기
그 다음 쿼리 요청을 적절한 서버로 분기할 때 사용할 AbstractRoutingDataSource 빈을 등록한다. DataSource 빈을 주입할 때 '같은 타입의 빈을 여러 개 찾았다' 라는 에러가 발생하지 않도록 @Qualifier 로 어떤 빈을 주입할 건지 지정한다.
@Configuration
public class DataSourceConfig {
...
@Bean(name = "routingDataSource")
public DataSource routingDataSource(@Qualifier(value = "masterDataSource") DataSource masterDataSource,
@Qualifier(value = "slaveDataSource") DataSource slaveDataSource) {
AbstractRoutingDataSource routingDataSource = new RoutingDataSource();
Map<Object, Object> targetDataSources = new HashMap<>();
// targetDataSources Map 객체에 분기할 서버들의 DataSource 빈을 저장
targetDataSources.put("master",masterDataSource);
targetDataSources.put("slave", slaveDataSource);
routingDataSource.setTargetDataSources(targetDataSources);
routingDataSource.setDefaultTargetDataSource(masterDataSource);
return routingDataSource;
}
...
}SqlSessionFactory 생성 메소드 인자 수정
AbstractRoutingDataSource 에서 결정된 DataSource 빈을 SqlSessionFactory 에서 사용할 수 있도록 메소드 인자를 수정한다.
@Configuration
@MapperScan(basePackages = "me.liiot.snsserver.mapper")
public class MyBatisConfig {
...
@Bean
public SqlSessionFactory sqlSessionFactory(@Qualifier(value = "routingDataSource") DataSource dataSource) throws Exception {
SqlSessionFactoryBean sqlSessionFactoryBean = new SqlSessionFactoryBean();
sqlSessionFactoryBean.setDataSource(dataSource);
sqlSessionFactoryBean.setMapperLocations(applicationContext.getResources("classpath:/mapper/**/*.xml"));
return sqlSessionFactoryBean.getObject();
}
...
}determineCurrentLookupKey() 로직 구현
위에서 설명한대로 현재 트랜잭션의 속성에 따라 targetDataSources 맵의 조회 키를 결정하기 위해 AbstractRoutingDataSource 클래스를 상속받아 determinCurrentLookupKey() 로직을 구현한다.
public class RoutingDataSource extends AbstractRoutingDataSource {
@Override
protected Object determineCurrentLookupKey() {
boolean isReadOnly = TransactionSynchronizationManager.isCurrentTransactionReadOnly();
return isReadOnly ? "slave" : "master";
}
}쿼리 요청에 따라 트랜잭션 속성 부여하기
Service Layer에 있는 다양한 메소드들 중에 어떤 메소드들은 단순 읽기 작업만 있다. 그런 경우 @Transactional 의 readOnly 옵션을 활성화하여 해당 메소드는 Slave 서버에서 요청을 처리하도록 한다. SpringBoot에서는 별도의 선언없이도 기본적으로 트랜잭션 기능이 활성화되기 때문에 그 외에 쓰기 작업이 포함된 메소드인 경우 따로 어노테이션을 붙이지 않는다.
@Service
@RequiredArgsConstructor
public class PostServiceImpl implements PostService {
...
// 읽기 작업만 포함된 메소드인 경우
@Override
@Transactional(readOnly = true)
@Cacheable(cacheNames = CacheNames.POST, key = "#postId")
public Post getPost(int postId) {
Post post = postMapper.getPost(postId);
return post;
}
...
// 쓰기 작업이 포함된 메소드인 경우
@Override
@Caching(evict = {@CacheEvict(cacheNames = CacheNames.POST, key = "#postId"),
@CacheEvict(cacheNames = CacheNames.FEED, key = "#user.userId")})
public void updatePost(User user, int postId, String content) throws AccessException{
boolean isAuthorizedOnPost = postMapper.isAuthorizedOnPost(user.getUserId(), postId);
if (isAuthorizedOnPost) {
postMapper.updatePost(postId, content);
} else {
throw new AccessException("해당 게시물의 수정 권한이 없습니다.");
}
}
...
}After Refactoring
위의 과정을 통해 MySQL 서버에 발생하는 부하를 분산시키고, 트랜잭션의 readOnly 속성의 활성화 여부에 따라 쿼리 요청을 분기할 수 있도록 코드를 작성했다. 하지만 이대로 실행하면 올바른 DataSource 와 Connection 객체를 얻어오지 못할 것이다. 그 이유는 트랜잭션의 동기화 시점과 Connection 객체를 얻어오는 시점이 다르기 때문이다. 이와 관련한 문제는 다음 글에서 다룰 예정이다.
진행 프로젝트
f-lab-edu/sns-itda
Contribute to f-lab-edu/sns-itda development by creating an account on GitHub.
github.com
이어지는 글
프록시 객체와 지연 로딩으로 DataSource 분기 처리 실패 해결하기
프록시 객체와 지연 로딩으로 DataSource 분기 처리 실패 해결하기 Overview 저번 글에서는 부하 분산을 위해 MySQL Replication 구성을 사용했고, 어플리케이션에서는 쿼리 요청에 따라 마스터 서버와 슬
chagokx2.tistory.com
'Java > ▶-----it;da' 카테고리의 다른 글
| 프록시 객체와 지연 로딩으로 DataSource 분기 처리 실패 해결하기 (0) | 2020.12.25 |
|---|---|
| Redis 성능 향상을 위한 Redis 세션 저장소와 캐시 저장소의 분리 (0) | 2020.12.03 |
| Redis Eviction 정책을 적용하여 효율적인 캐시 띄우기 (6) | 2020.11.24 |
| Spring Cache 적용으로 읽기 작업 성능 향상시키기 (0) | 2020.11.15 |
| 프로퍼티 파일을 이용한 외부 설정 주입과 운영 환경에 따른 프로퍼티 파일 분리 (0) | 2020.10.22 |
- Total
- Today
- Yesterday
- Django 해시태그
- Django 팔로우
- 장고
- Django 업로드
- Django 회원가입
- Django 회원 정보 수정
- Django 좋아요
- Redis Cache
- 북마크 어플리케이션
- 서점 어플리케이션
- Django 댓글
- Django Instagram
- Django 로그아웃
- query parameter
- Django application
- Django 프로젝트 생성
- python
- Django 검색
- Django 컬렉션
- Django
- Django 어플리케이션
- Redis
- Django 북마크
- java
- MySQL
- 파이썬
- Django 인스타그램
- Django User
- Django 비밀번호 수정
- Django 로그인
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 |